- Published on
카카오스캔 프로젝트 회고
- Authors

- Name
- Byun JongMin
목차
프로젝트 소개
연락처 동기화의 찝찝함 없이, 모르는 번호의 카카오톡 프로필을 확인할 수는 없을까?
카카오스캔은 이러한 일상 속의 사소한 불편함과 호기심에서 출발한 서비스입니다. 택배, 중고 거래, 업무 등 모르는 번호로 연락이 왔을 때 신원을 확인하기 위해 내 카카오톡에 원치 않는 연락처를 추가해야 하는 사용자들의 불편함을 해소하고자 기획하게 되었습니다.
현재 누적 가입자 3만 명과 MAU 4,000명의 실제 사용자가 이용하는 라이브 서비스를 2년 이상 직접 운영해 오고 있습니다. 이 과정에서 예기치 못한 여러 이슈들을 겪었지만 원인 분석부터 인프라/아키텍처 개선을 꾸준히 적용했으며, 현재는 큰 장애 없이 안정적으로 자동 구동되는 서비스로 발전시켰습니다.
본 포스팅에서는 서비스를 기획하며 고민했던 아키텍처 설계와 기술 도입 배경, 실제 운영 과정에서 맞닥뜨린 이슈를 어떻게 분석하고 해결해 나갔는지 트러블슈팅 과정을 공유하고자 합니다.
아키텍처
💡 이미지를 클릭하시면 확대 됩니다.
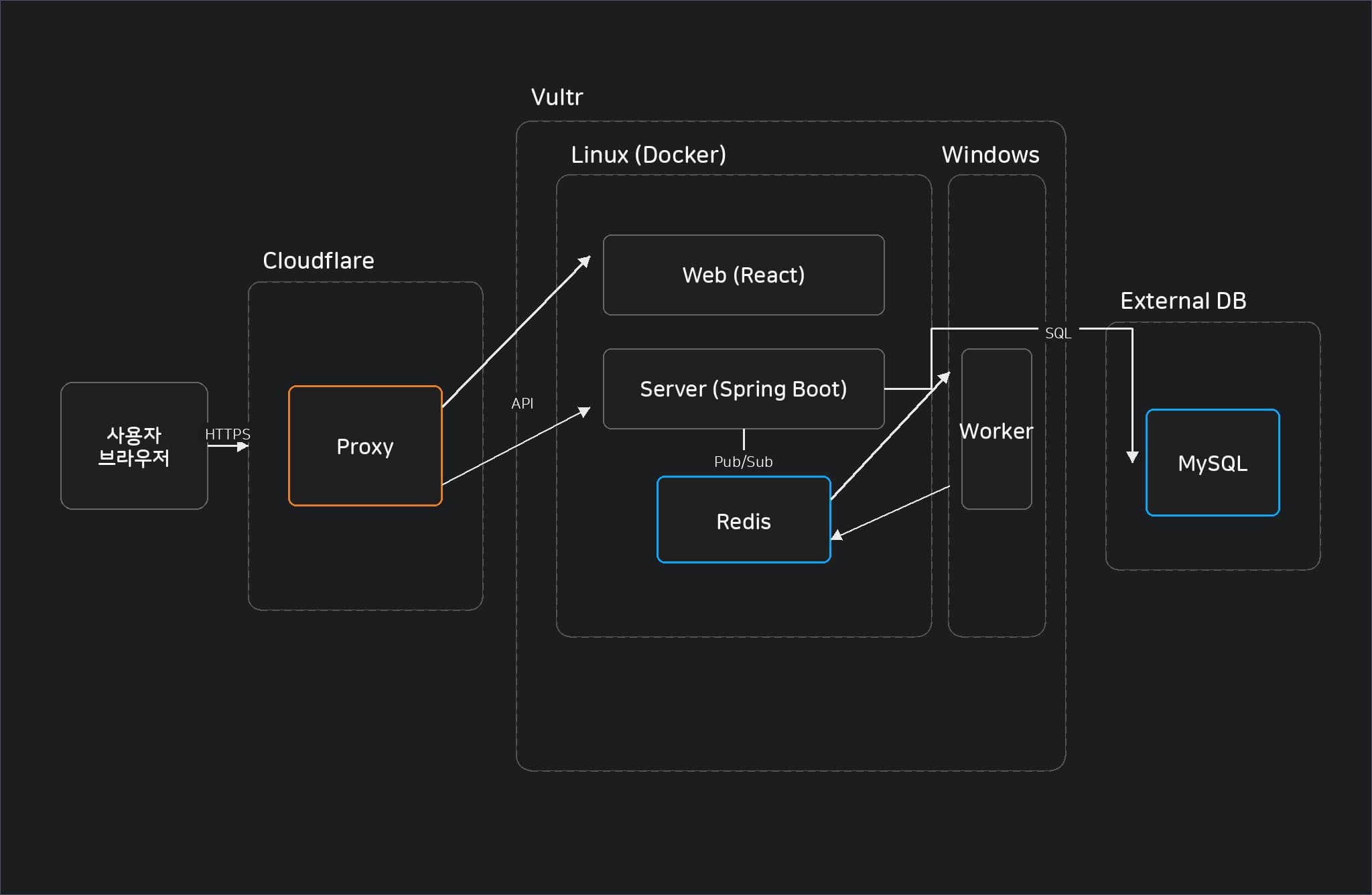
애플리케이션 아키텍처
인프라 아키텍처
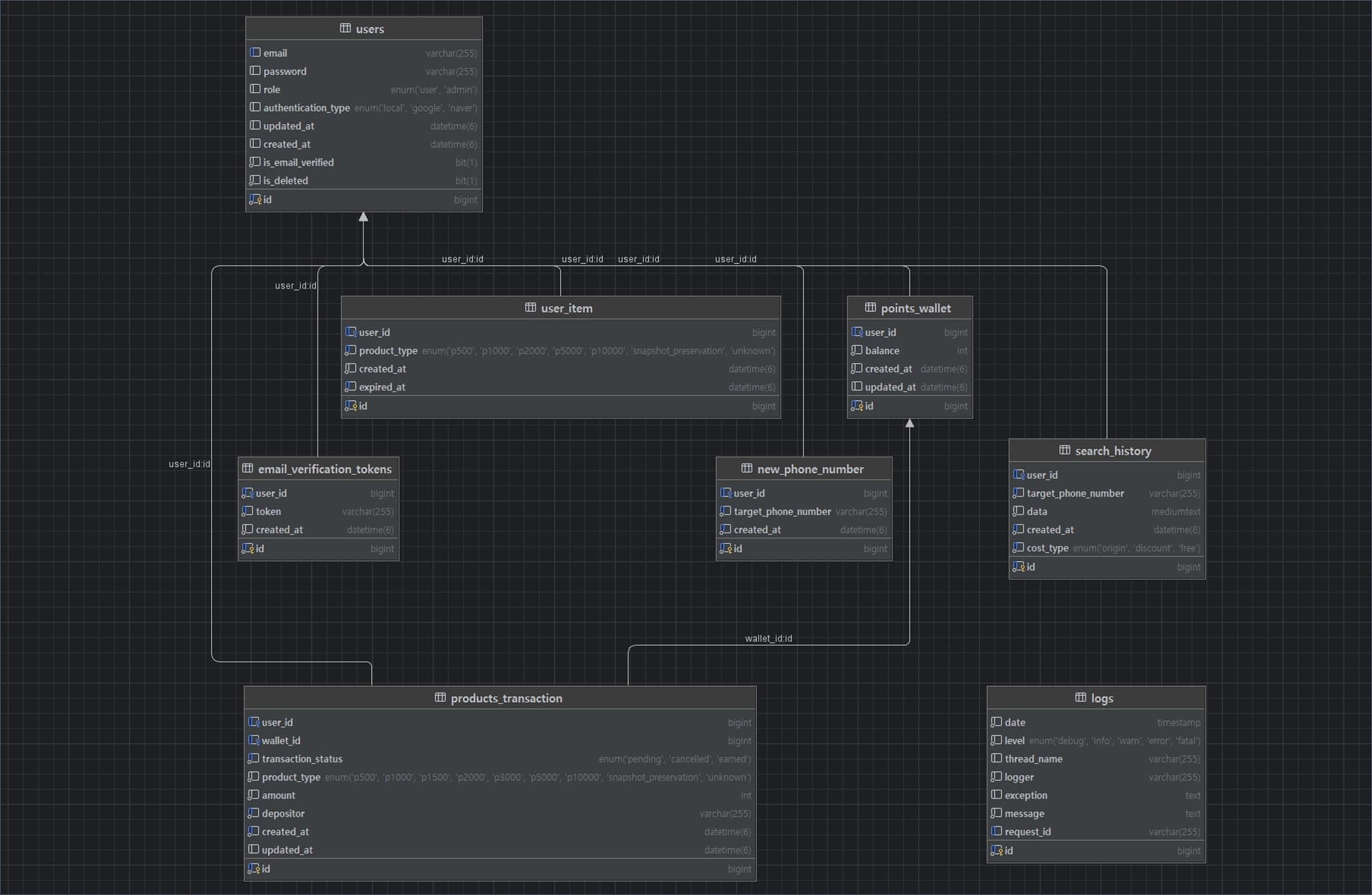
DB 다이어그램
시스템 구성 및 기술 도입 배경
Redis (Pub/Sub) - 오버엔지니어링 방지 및 인프라 리소스 최적화
초기 아키텍처에서는 Spring Boot 서버와 Windows의 Delphi 워커 간 양방향 통신을 위해, Java의 Netty 프레임워크와 Delphi의 TCP 소켓 컴포넌트를 사용했습니다. 하지만 네트워크 단절 시의 재연결 처리, 세션 관리 등 단순한 이벤트 전달 목적에 비해 구현이 지나치게 복잡해지는 오버엔지니어링으로 인해 서버와 워커 간 강한 의존성이 고민이었습니다.
이를 해결하고자 시스템을 비동기 이벤트로 분리하기 위해 메시지 큐를 도입하기로 검토했었습니다. 처음에는 대중적인 Kafka를 고려했으나 개인 프로젝트 규모에서 Zookeeper 클러스터 유지보수와 높은 메모리 요구량은 과도한 인프라 비용 부담으로 다가왔습니다.
저의 상황에서는 메시지의 영구 저장보다는 빠른 전송과 실시간성이 더 중요했기 때문에, 무거운 인프라를 새로 구축하는 대신 이미 캐시 스토어로 운영 중이던 Redis의 Pub/Sub 기능을 활용하는 것으로 아키텍처를 최종 변경했습니다.
결과적으로 기존 자원만을 활용하여 서버와 워커 간의 완벽한 비동기 통신 환경을 구축할 수 있었습니다.
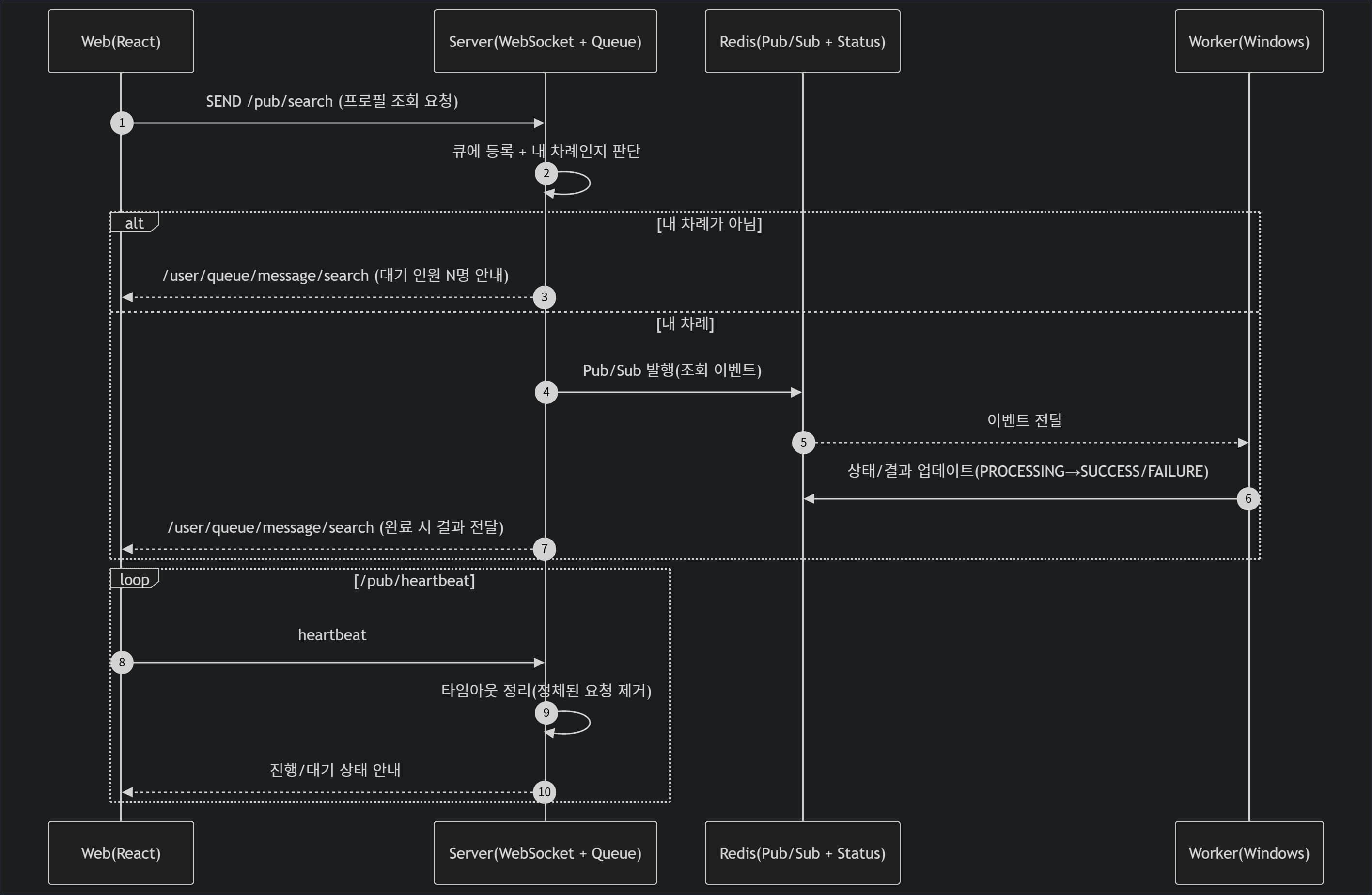
WebSocket - 작업 상태 복원과 비동기 큐잉
카카오톡 프로필 조회는 대상의 상태에 따라 수 초 이상의 시간이 소요될 수 있는 비동기 장기 실행 작업입니다. HTTP Request-Response 및 Polling 방식은 불필요한 서버 리소스를 낭비하기에, 클라이언트와 서버 간의 실시간 상태 동기화를 위해 WebSocket(STOMP)을 도입했습니다. 또한 세션 단절과 큐 정체 문제를 해결하기 위해 다음과 같은 방어 구조를 설계했습니다.
사용자가 세션 이탈 후 재접속 시 상태 복원
웹소켓의 가장 큰 단점은 클라이언트가 새로고침을 하거나 모바일 네트워크가 변경되어 세션이 끊어지면, 진행 중이던 작업의 상태를 잃어버린다는 것입니다. 이를 해결하기 위해
@EventListener(SessionSubscribeEvent.class)를 활용하여 재접속 감지 및 상태 복원 로직을 구현했습니다. 유저가 재접속하여 채널을 구독하는 순간, 서버는 해당 유저의 식별자를 기반으로 기존 작업 상태(WAITING, PROCESSING 등)를 조회합니다. 작업이 유효하다면 사용자가 페이지를 이탈했다가 돌아와도 기존의 대기열 순번과 진행 상황을 끊김 없이 그대로 이어서 안내받을 수 있도록 하였습니다.Heartbeat를 활용한 데드락 방지 및 리소스 정리
/pub/heartbeat 메시지가 수신될 때마다 작업 큐의 최상단을 확인하여, 워커의 장애나 일시적인 네트워크 오류로 인해 이벤트가 타임아웃에 빠졌는지 검사합니다. 만약 정체된 요청이 있다면 즉시 큐에서 제거하고 실패 처리를 함으로써, 대기열 데드락을 방지하고 시스템이 스스로 복구되도록 하였습니다.
Delphi - 카카오톡 프로필 조회를 위한 핵심 워커
핵심 기능인 카카오톡 프로필 조회는 Windows 환경에서 구동되는 카카오톡 프로세스를 직접 제어해야 하는 OS 종속적인 제약이 있었습니다. 이를 해결하기 위해 Delphi 언어를 활용한 Windows 전용 애플리케이션을 별도로 구현했습니다.
Vultr & Cloudflare - 운영 비용 절감 및 유지보수 효율화
개인의 사비로 서비스를 직접 운영하다 보니, 결국 가장 현실적인 고민은 운영 비용이었습니다. 현재 시스템을 지탱하는 두 대의 서버(Linux, Windows)는 모두 2 vCPUs, 4GB RAM, 100GB NVMe 스펙을 사용 중입니다. 초기 AWS 환경 당시 t3.medium 기준 Linux 및 Windows 인스턴스 요금은 기본적으로 월 90~100$ 이상의 고정 비용이 발생했었지만, Vultr로 전향 후 AWS 대비 50% 절감된 비용으로 운영 환경을 구축할 수 있었습니다.
인프라 유지보수 리소스를 줄이기 위해 Cloudflare를 도입했습니다. 무료 TLS 인증서 자동 갱신을 통해 성능 저하 없이 보안을 확보했으며, 인증서 만료 리스크를 제거하여 관리 부담 없이 핵심 비즈니스 로직 개발에만 집중할 수 있었습니다.
트러블슈팅
순차 처리 큐로 단일 워커 제약 개선
문제 상황 - 동시에 1건씩만 처리 가능한 외부 워커의 한계
프로필 조회는 Windows 환경에서 카카오톡 프로세스를 직접 제어하는 방식이었기 때문에, 외부 워커는 한 번에 하나의 요청만 처리할 수 있었습니다. 즉, 병렬 처리로 처리량을 높이는 접근은 애초에 불가능했고, 동시 요청이 몰릴수록 요청 순서가 꼬이거나 사용자마다 체감 대기 시간이 불안정해질 수 있는 구조적 제약이 있었습니다.
해결 과정
모든 조회 요청을 서버의 대기열에 먼저 적재하고, 큐의 최상단 요청만 워커로 전달하는 순차 처리 구조로 설계했습니다. 목적은 처리 순서를 통제 가능한 구조로 만드는 것이었습니다.
ConcurrentSkipListSet기반의 동시 접근 가능한 대기열 구현대기열은 다수의 웹소켓 세션이 동시에 접근하더라도 안전하게 동작할 수 있도록 ConcurrentSkipListSet 기반으로 구현했습니다.
정렬 기준은 요청 생성 시각을 1차 기준으로, 동일 시각 요청이 들어오는 경우를 대비해 유니크한 사용자 식별자를 2차 기준으로 두었습니다. 이를 통해 요청을 결정적인 순서로 처리할 수 있었고, 동시 요청 환경에서도 순서 충돌이나 중복 처리 가능성을 줄일 수 있었습니다.
SearchInMemoryQueuepublic class SearchInMemoryQueue implements QueueAggregate { private final ConcurrentSkipListSet<SearchMessage> set; public SearchInMemoryQueue() { this.set = new ConcurrentSkipListSet<>(Comparator.comparing(SearchMessage::getCreatedAt) .thenComparing(SearchMessage::getEmail)); } }큐의 최상단 요청만 실행하는 순차 처리 구조
서버는 대기열의 최상단 요청만 확인한 뒤, 해당 요청이 실제 처리 대상일 때만 Windows 워커로 이벤트를 발행하도록 구성했습니다. 이를 통해 외부 워커의 단일 처리 한계를 시스템 구조 안으로 포함했고, 워커가 감당 가능한 범위를 넘는 요청이 한꺼번에 실행되지 않도록 제어했습니다.
WebSocketController... Optional<SearchMessage> optionalPeekMessage = queue.peek(); .. boolean removedMessage = searchEventManagerService.removeTimeoutEventAndNotify(optionalPeekMessage.get()); boolean isUserTurn = searchEventManagerService.checkUserTurnAndNotify(message, optionalPeekMessage.get()); if (!removedMessage && isUserTurn) { searchEventManagerService.publishAndTraceEvent(optionalPeekMessage.get()); }대기 인원 안내를 통한 사용자 경험 보완
사용자가 아직 자신의 차례가 아닐 경우에는 즉시 실패시키거나 무응답 상태로 두지 않고, 웹소켓을 통해 현재 대기 중임을 안내했습니다. 차례가 도달하면 이후 처리 상태를 이어서 전달하도록 하여, 단일 워커 구조에서 발생하는 대기 시간을 사용자 입장에서 예측 가능한 경험으로 바꾸고자 했습니다.
SearchEventManagerService.checkUserTurnAndNotifypublic static final String SEARCH_QUEUE_WAITING = "대기 인원: %d명"; public boolean checkUserTurnAndNotify(SearchMessage searchMessage, SearchMessage peekSearchMessage) { boolean isUserTurn = searchMessage.getEmail().equals(peekSearchMessage.getEmail()); if (!isUserTurn) { int waitingCount = queue.size() - 1; messageDispatcher.sendToUser(new SearchMessage(searchMessage.getEmail(), format(SEARCH_QUEUE_WAITING, waitingCount), false)); return false; } return true; }
사용자 단위 분산 락을 적용하여 구매 신청 중복 방지
문제 상황 - 구매 신청 중복 클릭으로 인한 정합성 문제
사용자가 구매 신청 버튼을 연속으로 누르면 중복된 주문이 생성되는 문제가 있었습니다. 이런 상황을 제어하지 않으면 같은 사용자에 대해 여러 건의 결제 대기 주문이 쌓여 불필요한 데이터베이스 리소스가 낭비되므로, 네트워크 지연이나 사용자의 중복 클릭에도 항상 동일한 결과를 보장하는 멱등성 확보가 필수적이었습니다.
해결 과정
사용자 단위 분산 락으로 구매 신청 생성 구간 직렬화
구매 신청은 상품 유형별 processor가 제공하는 락 prefix와 사용자 ID를 조합해 Redisson 락을 획득한 뒤에만 처리하도록 구성했습니다. 즉 서로 다른 사용자의 요청은 병렬로 허용하되, 동일 사용자에 대한 구매 신청 생성만 직렬화해 짧은 시간 내 연속 클릭이나 중복 요청이 동시에 처리되지 않도록 했습니다.
ProductServicepublic void request(Long id, PaymentRequest request) { ProductTransactionProcessor<ProductTransaction> processor = productTransactionFactory.getProcessor(request.getProductType()); RLock lock = redissonClient.getLock(processor.getLockPrefix() + id); if (!RedissonLockUtils.withLock(lock, () -> { User user = userRepository.findByIdOrThrow(id); if (productTransactionRepository.existsPendingTransaction(user.getPointWallet())) { throw new PendingTransactionExistsException("대기 중인 결제 요청이 존재합니다. 이전 결제를 완료 또는 취소 후 신청해 주세요."); } ...이 구간에서 중요한 것은 단순히 락을 사용하는 것보다, 락을 트랜잭션보다 먼저 풀지 않는 것이었습니다.
RedissonLockUtils.withLock()는 트랜잭션 동기화가 활성화된 경우TransactionSynchronizationManager에 동기화를 등록하고,afterCompletion()에서만 락을 해제합니다.RedissonLockUtils.withLock... if (TransactionSynchronizationManager.isSynchronizationActive()) { TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronization() { @Override public void afterCompletion(int status) { try { if (lock.isHeldByCurrentThread()) { lock.unlock(); } } catch (Exception ignore) { } } }); } ...결과적으로 동일 사용자 기준으로는 한 번에 하나의 신청만 생성되도록 보장하는 구조가 되었습니다. 추가적으로 오래 방치된 거래는 스케줄러로 정리함으로써, 미완료 거래 누적이 쌓이는 것을 예방했습니다.
Cache-aside 패턴을 적용하여 응답시간 단축
문제 상황 - WebSocket 핫패스에서 반복적인 포인트 조회가 발생하던 구조
사용자가 보유 포인트 잔액을 확인할 때 WebSocket 메시지를 통해 현재 잔액을 전달해주고 있습니다. 사용자 상호작용 중 자주 호출되는 핫패스 구간이고, 쓰기 작업보다 조회 빈도가 훨씬 높았기 때문에, 매 요청마다 DB를 직접 조회하는 방식은 불필요한 I/O를 반복하게 만들고 응답시간을 늘리는 원인이 되었습니다.
@MessageMapping("/points")
public void handlePointBalance(Principal principal) {
cacheUpdateObserver.update(principal.getName(), pointService.getPoints(principal.getName()));
}
해결 과정
Cache-aside 패턴 적용
포인트 조회에는 Redis 기반의 cache-aside 패턴을 적용했습니다. 캐시에 값이 있으면 즉시 반환하고, 값이 없을 경우에만 DB에서 조회한 뒤 Redis에 저장하도록 구성했습니다. 포인트 조회는 같은 사용자가 짧은 시간 안에 여러 번 반복할 가능성이 높고, 동일한 값을 매번 DB에서 다시 읽어오는 비용은 불필요했기 때문입니다. 또한 TTL은 3분으로 짧게 두어, 캐시 효율을 얻되 오래된 값이 장시간 남는 위험은 과도하게 키우지 않도록 했습니다.
정합성 보장
캐시를 붙일 때 가장 신경 쓴 부분은 성능보다 정합성이었습니다. 만약 포인트 차감이 진행 중인데 캐시된 이전 잔액을 그대로 반환하면, 사용자에게 잘못된 포인트가 노출될 수 있습니다. 이를 방지하기 위해 조회 시점에 먼저 사용자 단위 락의 점유 여부를 확인하고, 수정 중이라면 캐시 조회를 진행하지 않고 예외를 발생시키도록 했습니다.
@Transactional(readOnly = true)
public int getPoints(String userId) {
RLock lock = redissonClient.getLock(LOCK_USER_POINTS_KEY_PREFIX + userId);
if (lock.isLocked()) {
throw new ConcurrentModificationException("points data is currently being modified");
}
final String key = POINT_CACHE_KEY_PREFIX + userId;
Supplier<Integer> supplier = () -> {
User user = userRepository.findByEmailOrThrow(userId);
return user.getPointWallet().getBalance();
};
return RedisCacheUtils.getFromCacheOrSupplier(
integerCacheStorePort,
key,
Integer.class,
supplier,
3,
TimeUnit.MINUTES
);
}
성능 측정 결과
캐시 사용 경로와 DB 직접 조회 경로를 분리하고 내부 벤치용 엔드포인트를 추가해 비교 측정을 진행했습니다.
// 캐시 사용
@Transactional(readOnly = true)
public int getPointsCached(String userId) {
ensureNotLocked(userId);
final String key = POINT_CACHE_KEY_PREFIX + userId;
Supplier<Integer> supplier = () -> loadPointsFromDb(userId);
return RedisCacheUtils.getFromCacheOrSupplier(
integerCacheStorePort,
key,
Integer.class,
supplier,
3,
TimeUnit.MINUTES
);
}
// 캐시 미사용 (항상 DB 조회)
@Transactional(readOnly = true)
public int getPointsDbOnly(String userId) {
ensureNotLocked(userId);
return loadPointsFromDb(userId);
}
@GetMapping("/internal/bench/points")
public BenchResult benchPoints(
@RequestParam String userId,
@RequestParam(defaultValue = "cache-hit") String mode,
@RequestParam(defaultValue = "50") int warmup,
@RequestParam(defaultValue = "200") int n
) {
for (int i = 0; i < warmup; i++) {
runOnce(userId, mode);
}
long[] latNanos = new long[n];
for (int i = 0; i < n; i++) {
long t0 = System.nanoTime();
runOnce(userId, mode);
latNanos[i] = System.nanoTime() - t0;
}
Arrays.sort(latNanos);
return new BenchResult(
mode,
warmup,
n,
Arrays.stream(latNanos).average().orElse(0) / 1_000_000.0,
percentileMs(latNanos, 0.50),
percentileMs(latNanos, 0.95),
percentileMs(latNanos, 0.99),
latNanos[0] / 1_000_000.0,
latNanos[latNanos.length - 1] / 1_000_000.0
);
}
측정 모드는 다음 세 가지로 나누었습니다.
cache-hit캐시가 이미 채워진 상태에서 조회cache-miss매 요청마다 캐시를 삭제한 뒤 조회db캐시를 사용하지 않고 항상 DB 조회
| mode | warmup | iterations | avg(ms) | p50(ms) | p95(ms) | p99(ms) | min(ms) | max(ms) |
|---|---|---|---|---|---|---|---|---|
| cache-hit | 50 | 300 | 38.08 | 37.53 | 41.67 | 46.00 | 35.67 | 49.25 |
| cache-miss | 20 | 100 | 60.04 | 58.78 | 66.99 | 67.56 | 54.07 | 70.18 |
| db | 20 | 100 | 56.49 | 56.13 | 60.20 | 61.82 | 53.82 | 62.41 |
비록 cache-miss가 db보다 오히려 더 느리게 나왔지만(캐시 적재 비용까지 포함되므로), 프로젝트 상황에서 포인트 잔액 조회는 같은 사용자가 짧은 시간 안에 잔액을 다시 확인하는 일이 많고, 쓰기보다 읽기 비중이 높았기 때문에 cache-aside 적용 효과가 명확하게 드러났습니다.
- avg 응답시간: 56.49ms → 38.08ms → 약
32.6%단축 - p95 응답시간: 60.20ms → 41.67ms → 약
30.8%단축 - 절대 지연 감소폭: p95 기준 약
18.53ms감소
p95 기준으로 응답시간이 60ms대에서 40ms 초반대로 내려오면서, 반복 조회가 많은 WebSocket 핫패스 구간에서 응답 지연을 개선할 수 있었습니다.
Phone Link 후킹 기반 무통장 입금 자동 확인
문제 상황 - 무통장 입금 확인을 수동으로 확인해서 결제 완료 처리를 해야하는 상황
무통장 입금 기반 결제는 사용자가 송금한 뒤, 서버가 외부 결제 API를 직접 조회할 수 없는 경우가 많아 관리자의 수동 확인에 의존하는 경우가 빈번합니다. 이 문제를 해결하기 위해 은행 입금 알림 SMS를 이벤트 소스로 삼아 자동으로 결제 완료까지 이어붙일 수 없을까?라는 관점에서 접근했습니다.
핵심 아이디어는 은행 거래 내역을 주기적으로 폴링하는 것이 아니라, 휴대폰에 도착한 입금 알림이 Windows의 Phone Link 앱까지 전달되는 순간을 가로채는 것이었습니다.
참고: Phone Link는 Microsoft에서 제공하는 앱으로, 윈도우 10/11 PC와 안드로이드 또는 아이폰을 동기화하여, PC에서 문자 발송, 통화, 알림 확인, 사진 확인, 앱 실행을 지원하는 무료 도구입니다.
해결 과정
아이디어는 입금 내역 조회가 아니라 입금 알림 발생을 즉시 반응하는 이벤트 기반 파이프라인을 구현하는 것 이었습니다. 다음과 같은 흐름으로 입금 알림 도착 이후 결제 완료까지를 거의 실시간으로 처리할 수 있었습니다.
- CreateRemoteThread API로 Phone Link 프로세스에 쓰레드를 생성하고 LoadLibrary API를 호출하여 Hook.dll을 주입
- Hook.dll이 내부의 알림 처리 루틴을 패턴 스캔으로 찾아 인라인 후킹
- 필터링된 알림 JSON을 Redis Pub/Sub 토픽으로 즉시 발행
- 서버가 Redis 구독 후 SMS 본문을 파싱해 대응되는 PENDING 주문을 COMPLETED로 변경
구체적인 트러블슈팅 과정은 hosthook-pay 회고에 별도로 정리해 두었습니다.
환경적 문제
지금은 이 방식 대신에 외부 SaaS API를 활용해서 WebHook 기반으로 결제를 자동 처리하고 있습니다. 이전 방식 또한 기능상 문제는 전혀 없었지만, SMS 알림을 놓치지 않고 전달하기 위해서는 24시간 iPhone과 PC의 Bluetooth 연결을 유지해야 했습니다. 저의 상황에서는 PC를 24시간 가동하기가 어려운 상황이였기에 아쉽지만 비용이 들더라도 외부 SaaS를 채택하게 되었습니다.
결제 승인 API 응답 시간 단축
문제 상황 - 결제 승인 API가 핵심 상태 변경 외 부수효과까지 함께 처리하던 구조
초기 결제 승인 API는 단순히 거래 상태를 PENDING → EARNED로 바꾸는 것에서 끝나지 않았습니다. 승인 직후 사용자 포인트 잔액을 갱신해 캐시에 반영하고, 웹소켓으로 잔액을 푸시하고, 구매 완료 메일까지 발송해야 했기 때문에 하나의 요청 안에 여러 부수효과가 함께 묶여 있었습니다. 이런 구조로 인해 캐시 갱신/이벤트 발행/이메일 발송 중 하나라도 느려지면 API 응답이 지연 됐었습니다.
해결 과정
핵심 상태 변경과 부수효과를 분리
결제 승인 API의 책임을 먼저 분리했습니다. 요청 스레드에서는 핵심 도메인 상태만 반영하고, 이후 필요한 후처리는 비동기 이벤트로 묶어 발행하도록 변경했습니다.
결제 승인 성공과승인 이후 해야 할 일들을 같은 트랜잭션 안에서 한 번에 처리하지 않고 경계를 명확히 나눴습니다.ProductService@Transactional public void approve(Long productTransactionId) { processProductTransaction(productTransactionId, (processor, transaction) -> { // 상태 변경 processor.approve(transaction); transaction.approve(); // 부수효과 이벤트 int newBalance = transaction.getWallet().getBalance(); events.publishEvent(new ApprovalSideEffectsEvent( transaction.getUser().getEmail(), newBalance, transaction.getProductType().getDisplayName(), System.getenv("CURRENT_BASE_URL"), transaction.getId() )); ... }AFTER_COMMIT로 묶어 커밋 전 부수효과 실행을 방지
후처리 핸들러는
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)로 선언돼 있습니다. Spring 문서 기준으로@TransactionalEventListener는 기본적으로 트랜잭션 커밋 단계에 바인딩되며,AFTER_COMMIT이면 트랜잭션이 실제로 성공적으로 커밋된 뒤에만 실행됩니다. 이로 인해 승인 데이터가 아직 DB에 반영되기 전에 캐시를 먼저 갱신하거나, 커밋 실패인데도 결제 완료 메일이 먼저 발송되는 문제를 피할 수 있었습니다.ApprovalSideEffectsHandler@Component @RequiredArgsConstructor public class ApprovalSideEffectsHandler { private final CacheUpdateObserver cacheUpdateObserver; private final EventPublisher eventPublisher; ... @Async("taskExecutor") @TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT) public void handle(ApprovalSideEffectsEvent e) { // 포인트 잔액 캐시 업데이트 cacheUpdateObserver.update(e.email(), e.newBalance()); // 결제 완료 이메일 발송 eventPublisher.publish( OTHER_EVENT_TOPIC.getTopic(), new ProductPurchaseCompleteEvent(e.email(), e.productName(), e.baseUrl()) ); ... } }
개발자 도구의 Network 탭에서 측정 결과, 응답시간은 약 3,000ms → 150ms 이내로 개선되었습니다.
운영 장애 대응: UnknownHostException과 DNS 이슈
문제 상황
서비스가 안정적으로 운영되던 중, 어느 날 갑자기 서버에서 UnknownHostException이 발생하며 서비스 장애가 일어났습니다. 당시 배포된 코드가 없었던 상황에서 발생한 예기치 못한 인프라 장애였습니다.
해결 과정
예외의 정의를 보고 애플리케이션 내부 로직의 문제가 아니라 서버가 도메인 주소를 IP로 변환하지 못하는 네트워크 계층의 문제라고 생각 했습니다. 운영 중인 Linux 서버(Vultr)에 SSH로 접속하여 상태를 점검했습니다. 대상 도메인에 대해 curl과 ping 테스트를 진행해 연결 실패를 확인한 후, 장애의 범위를 좁히기 위해 nslookup 명령어로 도메인 질의를 수행했는데, Vultr에서 기본으로 할당해 준 통신사의 디폴트 DNS 서버가 일시적인 먹통 상태에 빠져 질의에 응답하지 못하고 있음을 알게되었습니다.
원인 파악 후, 서버의 DNS 설정 파일인 /etc/resolv.conf를 열어 네임서버를 장애가 난 기본 DNS에서 글로벌 공용 DNS(Google 8.8.8.8 / Cloudflare 1.1.1.1)로 변경했습니다. 이후 도메인 질의가 정상적으로 이루어지며 서비스가 복구되었습니다.
cat <<'EOF' | sudo tee /etc/resolv.conf >/dev/null
nameserver 1.1.1.1
nameserver 8.8.8.8
options timeout:2 attempts:2
EOF